Equality with Multiple Values, Preserving Sort for Pagination
In the previous post, I've created the following index to quickly find the last videos in one category (reminder: 1 means ASC, -1 means DESC):
db.youstats.createIndex({
category: 1 , // for Equality on category
publishedDate: -1 , // for Sort within each category
duration: 1 , // for additional Range filtering
});
MongoDB can use this index even for queries that do not have an equality predicate on "category". Not many databases offer this possibility, and it helps to limit the number of indexes to create for an OLTP application.
Access pattern: videos in a list of categories
I ran the same query as in the previous post, but with a list of categories instead of one: Music, Entertainment and Film. This fits in the same access pattern and doesn't need another index. Up to 200 values in the list, MongoDB runs an index scan for each value and merges the sorted results of each:
db.youstats.find({
category: { $in: ["Music", "Entertainment", "Film"] } ,
duration: { $gt: 10 } ,
},{
category: 1 ,
author: 1 ,
title: 1 ,
duration: 1 ,
type: 1 ,
publishedDate: 1 ,
}).sort({ publishedDate: -1 }).limit(10).explain("executionStats")
In total, 12 keys were read to find the 10 documents for the result, which is very efficient:
nReturned: 10,
executionTimeMillis: 5,
totalKeysExamined: 12,
totalDocsExamined: 10,
Each value from the list was a seek into the B-Tree for each category:
indexBounds: {
category: [ '["Entertainment", "Entertainment"]' ],
publishedDate: [ '[MaxKey, MinKey]' ],
duration: [ '(10, inf.0]' ]
},
keysExamined: 6,
seeks: 1,
...
indexBounds: {
category: [ '["Film", "Film"]' ],
publishedDate: [ '[MaxKey, MinKey]' ],
duration: [ '(10, inf.0]' ]
},
keysExamined: 1,
seeks: 1,
...
indexBounds: {
category: [ '["Music", "Music"]' ],
publishedDate: [ '[MaxKey, MinKey]' ],
duration: [ '(10, inf.0]' ]
},
keysExamined: 5,
seeks: 1,
Such OR-Expansion (the IN could be an OR), exists in other databases, but MongoDB goes further by using a sort-merge algorithm on top of it to preserve the order from each index scan (called "explode for sort optimization"), visible in the execution plan with a SORT_MERGE stage. This sort preservation is vital in OLTP scenarios, especially for pagination queries, as it avoids scanning all documents to sort them for page retrieval.
Such technique necessitates a list of values for the query planner to define the index bounds, so it cannot be directly used by the opposite $nin or $neq. However, another optimization allows getting such list very efficiently.
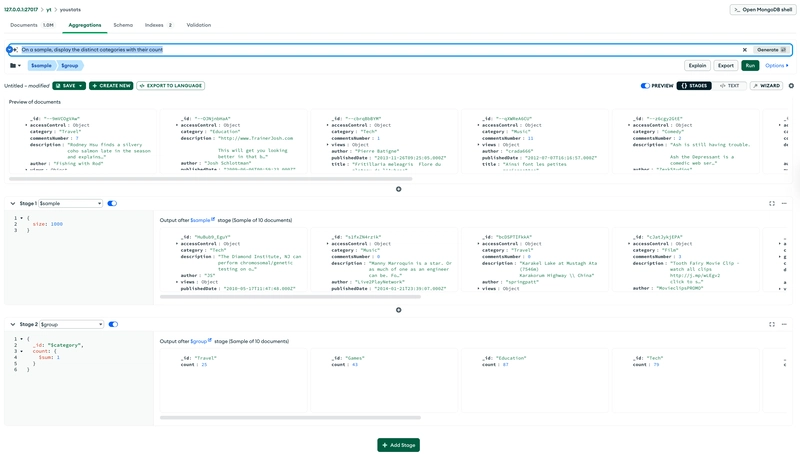
Access pattern: distinct categories (with Loose Index Scan)
This gets the distinct value for "category":
db.youstats.distinct("category")
[
'3', '4',
'5', 'Animals',
'Autos', 'Comedy',
'Education', 'Entertainment',
'Film', 'Games',
'Howto', 'Music',
'News', 'Nonprofit',
'People', 'Shows',
'Sports', 'Tech',
'Trailers', 'Travel'
]
It is extremely fast and to explain why I run the same in an aggregation pipeline with explain:
db.youstats.aggregate([
{ $group: { _id: "$category" } }
]).explain("executionStats").stages[0]["$cursor"].executionStats
{
executionSuccess: true,
nReturned: 20,
executionTimeMillis: 0,
totalKeysExamined: 20,
totalDocsExamined: 0,
executionStages: {
isCached: false,
stage: 'PROJECTION_COVERED',
nReturned: 20,
executionTimeMillisEstimate: 0,
works: 21,
advanced: 20,
transformBy: { category: 1, _id: 0 },
inputStage: {
stage: 'DISTINCT_SCAN',
nReturned: 20,
executionTimeMillisEstimate: 0,
works: 21,
advanced: 20,
keyPattern: { category: 1, publishedDate: -1, duration: 1 },
indexName: 'category_1_publishedDate_-1_duration_1',
isMultiKey: false,
multiKeyPaths: { category: [], publishedDate: [], duration: [] },
direction: 'forward',
indexBounds: {
category: [ '[MinKey, MaxKey]' ],
publishedDate: [ '[MaxKey, MinKey]' ],
duration: [ '[MinKey, MaxKey]' ]
},
keysExamined: 20
}
}
}
By examining only 20 keys, MongoDB was able to find the distinct values of the first field of the index, skipping values while scanning the B-Tree. Not many databases can do that (as exposed in the PostgreSQL Wiki), and it can be combined with the loose index scan we have seen above.
Access pattern: for any category, sorted by publishing date
When you know that there are less than 200 distinct value in the first field of the key, you can use the same index even without a filter on it, using db.youstats.distinct("category") which is fast:
db.youstats.find({
category: { $in: db.youstats.distinct("category") },
duration: { $gt: 10 },
},{
category: 1 ,
author: 1 ,
title: 1 ,
duration: 1 ,
type: 1 ,
publishedDate: 1 ,
}).sort({ publishedDate: -1 }).limit(10).explain("executionStats")
It had to examine only 29 keys out of one million to get the ten documents for the result:
nReturned: 10,
executionTimeMillis: 1,
totalKeysExamined: 29,
totalDocsExamined: 10,
This can also be used to find all categories except one:
db.youstats.distinct("category").filter(
category => category !== "People"
)
Of course, an index without "category" in front will serve this query slightly better, but not having to create a new index is a big advantage for general purpose applications that cover multiple use cases.
Skip Scan for all categories
To run my query for all categories, I extracted the list, with DISTINCT_SCAN to inject it for a MERGE SORT. I can read all categories with category: { $gt: MinKey } but this is a single IXSCAN that returns entries sorted by category before published date, which must go through a SORT:
db.youstats.find({
category: { $gt: MinKey } ,
duration: { $gt: 10 } ,
},{
category: 1 ,
author: 1 ,
title: 1 ,
duration: 1 ,
type: 1 ,
publishedDate: 1 ,
}).sort({ publishedDate: -1 }).limit(10).explain("executionStats")
...
stage: 'FETCH',
nReturned: 10,
executionTimeMillisEstimate: 406,
works: 1006099,
advanced: 10,
needTime: 1006088,
docsExamined: 10,
...
stage: 'SORT',
nReturned: 10,
executionTimeMillisEstimate: 405,
works: 1006099,
advanced: 10,
needTime: 1006088,
sortPattern: { publishedDate: -1 },
memLimit: 104857600,
limitAmount: 10,
totalDataSizeSorted: 1506,
inputStage: {
stage: 'IXSCAN',
nReturned: 991323,
executionTimeMillisEstimate: 237,
works: 1006088,
advanced: 991323,
needTime: 14764,
keyPattern: { category: 1, publishedDate: -1, duration: 1 },
indexName: 'category_1_publishedDate_-1_duration_1',
isMultiKey: false,
multiKeyPaths: { category: [], publishedDate: [], duration: [] },
direction: 'forward',
indexBounds: {
category: [ '(MinKey, MaxKey]' ],
publishedDate: [ '[MaxKey, MinKey]' ],
duration: [ '(10, inf.0]' ]
},
keysExamined: 1006087,
seeks: 14765,
...
Even if it has read and sorted a million index entries, this query executed in less than half a second because it didn't have to fetch the documents, as the index covered the filtering and sort fields. If an index is not the best for avoiding a sort, it may still be sufficient for pagination queries. Always look at the execution plan and ensure that the FETCH operation doesn't read more documents than necessary.
This post illustrates that you may not need to create separate indexes for new queries. An optimal index for one use case can still effectively serve others. In these examples, the most selective filtering was achieved through sort().limit() pagination, making the best index include the sorting field in its key. A prefix with few values still provides good performance, whether used with $eq or $in, and a suffix can cover additional filters or projections.
{kind=link}
{kind=link}
{kind=link}
{kind=link}